“The project”, Phase 1 - inheriting a mess
A project I was involved in inherited a system from a not-very-good team who liked architecture more than quality. It was at the point a failed project, it wasn’t even deployable. The system it was supposed to replace couldn’t be turned off and the smell of failure was in the air. It was a core piece of the client’s digital estate and failure was not a pretty option.
“It was a core piece of the client’s digital estate and failure was not a pretty option.”
Phase 1 of the rescue mission was fire fighting. Whatever it took to get the hot mess we’d been handed running and the old system turned off. The levels of technical debt actually went up during this time, but this was an intentional strategy that allowed us to ship something that basically worked in a reasonable timescale.
Now for Phase 2, but what to do?
Let’s go back a bit and see if you’ve got any signs of similar problems:
Signs you have a technical debt problem
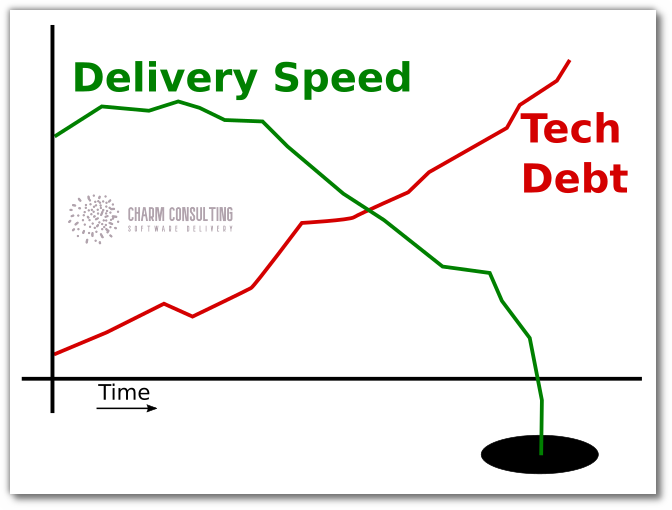
- Long lead time on features (more than a month from idea to shipping).
- Developers complaining about “technical debt” or “bad code”.
- Low throughput of features, you can only get one or two pieces of user value out of each two week sprint, if that.
Listen to your engineers, what are they saying?
Things I’ve heard said before that mean you are in this boat:
- “We can’t ship this because the code is terrible!”
- “We need to rewrite x/y, or maybe even the entire system!”
- “I think I’m going to quit, I hate this project!”
- “I can’t predict how long this will take because there are so many gremlins in here!”
- “This system is impossible to understand”
- “There’s no test coverage”
“I think I’m going to quit, I hate this project!”
~ Your developers
Watch out for
- General poor morale - are your developers listless or enthusiastic?
- Can do attitudes that have faded (rapidly) into despondency.
- Features delivered are always barely good enough and maybe even outright buggy even though you have good people.
- You have a heavy reliance on manual QA.
- The team is stuck doing big-bang deploys that sometimes fail or get rolled back.
“There’s a problem with this release, we have to roll it back (yet again)”
~ Your operations people
If it’s not immediately obvious, you can flush these things out with:
- Regular retros (assuming you are able to create a safe space, a topic for another day).
- One-to-one conversations with each developer.
We have a problem but how do I fix it?
“Isn’t that the developers’ job?”
Technical debt is often a result of organisational problems, and as such the solution is not purely technical (although the actual work of fixing the software largely is).
You need the right organisational structure
It’s important to have clear lines of responsibility and the ability for a senior technical leader such as a CTO or Head of Engineering to make and defend architectural and cultural decisions that may sometimes be at odds with short term goals, and may even require other parts of the business to do things differently. There’s a 3-part podcast series on this subject you can find here which is worth a listen: “Developing Leadership - A Deep Dive Into Engineering Leadership Roles, Part 1” (part 2 / part 3)
You need great technical people
Make sure you have a capable development team. Any sub-standard developers on your team will drag the whole thing down.
Now that you know your team is A++ you can:
Give the team the green light
- Make it clear you are all in this together and you see paying down the debt as a priority.
- Get buy-in from your project sponsors to do the hard things needed to get back to great shipping.
- Listen to calls to rewrite but be wary of okaying them as they are often the road to a different ruin and are often born out of frustration rather than rational thought.
- Give the team air-cover from the rest of the organisation to adjust the balance of feature vs quality improvement in sprints.
- Ask questions about the underlying reasons for the problems, don’t switch off just “because it’s technical”.
- Provide business context, which areas of the system are likely to need new features next, are there any deadlines or priorities coming down the line that would affect which problems to fix first?
- Give the team a ratio for the sprints, say 30% pay-down time, 70% feature time but don’t actually enforce it, it’s more about giving permission to make things better.
- Continue to ship user-value and build credibility as a delivery team within the organisation, don’t just disappear for months “because debt”!
- Trust your team, if you have the right people and give them the backing and space they will turn the system around.
- Make it clear that nothing is off limits - is the original architecture flawed? That can be fixed.
- Encourage tackling harder problems properly, like continuous delivery and end to end automated regression testing.
- Emphasise the iterative approach. Many small bets over one big rewrite.
- Talk about best practices and see how far away your organisation is, what examples / videos / blog posts / speakers can people bring to the team to learn from and aspire to?
- Make sure end users are involved via “user research” - maybe a particularly thorny area isn’t something they even care about and can be turned off, or replaced with a far simpler solution.
- Celebrate successes.
- Spread the love to the wider organisation. Be visibly successful.
How will I know when I’ve got there?
- Your dev team morale will go through the roof, they will deliver more than you asked instead of less.
- Cycle time will fall dramatically.
- Your defect rate will fall.
- Your users will be happier.
- You can achieve more with less.
“The project”, Phase 2 - getting to good
Let’s continue the story of the real project we talked about in Phase 1. Where we left off we’d done some firefighting, proved ability to deliver, and got our heads above water enough to think bigger about how we can fix the mess we have.
Now that there was a just-about-deployable system we could iterate on quality.
The first part was small wins, rewriting some of the worst coding in localized areas just to feel like things are getting better without having to take big risks. Adding unit tests here and there but without taking big risks with the entire system and architecture. This was done with nothing more than a bit of permission and encouragement from leadership on the team.
The next thing was building a better structured and tested side-by-side version of the code that serves the web traffic and having a system for routing different URL paths to old and new (in this case the old was too bad to cost-effectively iterate to a better place, this is unusual and should be a last resort). This is a slightly bigger step but not as big as tackling some of the broader issues with the micro-service architecture problems in this system. It could be done while continuing to ship features and without ruffling any feathers in the broader organisation.
At this point the team had earned a reputation for shipping user value in spite of difficult circumstances and were ready to have some of the harder conversations with the broader organisation about the work needing to be done to go from “tolerably bad” to “great”.
“The team had earned a reputation for shipping user value”
With a bit of breathing space earned, and so many things that were bad that could be fixed at every level of the system, the next thing was for the developers to get their heads together over Zoom and build a prioritized “debt backlog” in Trello. Your team can use whatever works for them, but keep it lightweight. This was huge for morale. Just knowing that there was now a plan for getting from where we were to something that would be a pleasure to work on, and that there was the backing of the organisation immediately made everyone feel better. Can you say “staff retention”?!
Let the debt linger for too long and your best people will leave. Make no mistake; great programmers don’t need to waste their time working on terminally broken projects that ship little value. One of our best developers nearly left because of friction with the organisation for trying to make things better.
As per the new tech debt plan in Trello the next thing was to start rearranging some of the code and micro-service organisational choices, this requires assistance and interaction with “DevOps” and operations people as it touches infrastructure and build system changes. Picking an area that would prove our ability to make these changes was critical. A couple of sprints later and this concept was proven and we had a base for making any changes we needed to from there on. Now that the ball is rolling, the team is enabled to mould the system into a high quality well tested codebase that can support the business needs for agility and value delivery for many years to come. It would now be hard to stop it getting there.
The journey never ends but you get to a point where the level of technical debt is no longer soul and productivity destroying and is instead the normal background level that any high-performing team will have lurking in areas that matter less.
The additional challenge of remote
Communication can be variable at the best of times, and tends to be worse when people are depressed about the state of what they have to work on. People withdraw, give up and leave.
It’s important to have regular scheduled discussions at each level (tech, business+tech etc) that can cover whatever is most pressing. We settled on two “tech chat” sessions a week, which kept things moving well. Do something to make it clear that things are on the up and everyone is pulling together.
Make it safe to talk about how bad things are and were.
Take action
If your project has any of these warning signs, don’t delay in taking positive action. There is never a better time than now.
About us
This story and project has been a collaboration between eSynergy Solutions and Charm Consulting Ltd.
- Charm Consulting - delivery focussed software consultancy.
- eSynergy Solutions - medium to large scale assessments, delivery and transformation.
If you can relate and want some help, drop me a mail at tim@charmconsulting.co.uk
Further reading
For a down and dirty technical guide to technical debt see Tim’s article here: https://timwise.co.uk/2020/07/09/approaches-to-refactoring-and-technical-debt/ - this might be a useful basis for discussion with your developers about the particular challenges of your project.